
10 Mars 2025
Dans un premier temps, nous allons examiner quatre petites histoires pour illustrer ce qui peut arriver lorsque des juristes utilisent l’intelligence artificielle sans comprendre ce qu’ils font… ou lorsque des ingénieurs tentent de résoudre des problèmes de droit sans tenir compte des spécificités du domaine.
Ensuite, nous essayerons de comprendre les principes de base du fonctionnement des intelligences artificielles modernes, et finalement nous discuterons de ce qui vous concerne peut-être le plus en tant qu’utilisateurs de ces systèmes: comment les évaluer, et s’assurer que vous sachiez déterminer s’il est raisonnable et éthique pour vous de les utiliser dans votre pratique.
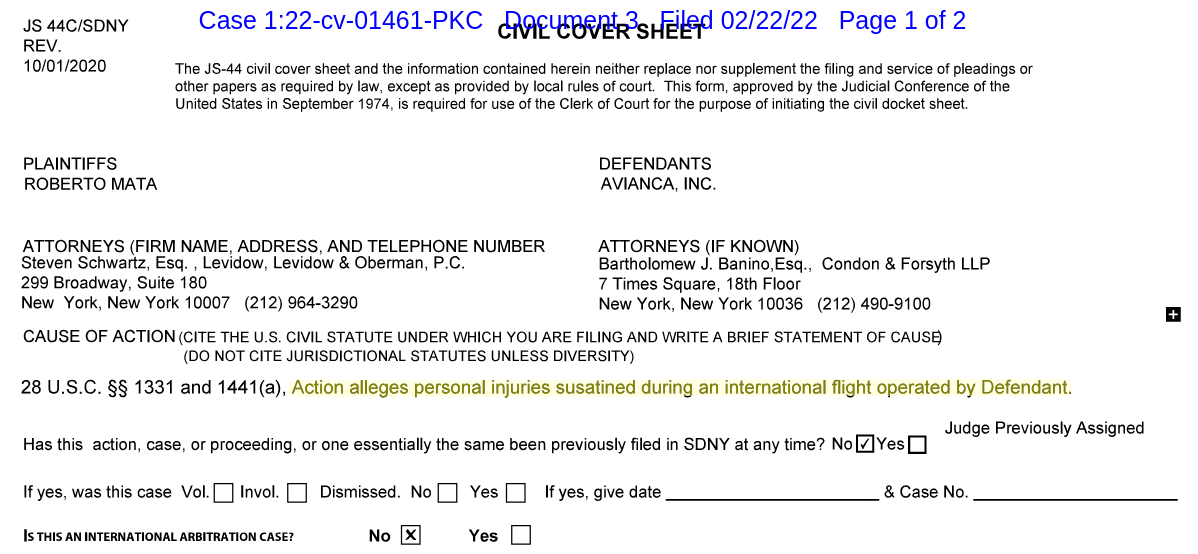
Mata v. Avianca est une affaire qui, normalement, n’aurait du intéresser personne mis à part les parties impliquées. En 2022, Roberto Mata attaque la compagnie aérienne Avianca en justice, car il dit avoir été blessé par un chariot durant un vol, et estime Aviance responsable. La compagnie a depuis fait faillite, ce qui rend la situation juridiquement plus complexe.

Avianca, de son côté, veut que l’affaire soit classée sans suite parce que le délais de prescription est dépassé. S’ensuit un argumentaire légal qui n’a toujours rien de particulier.

L’avocat de la partie civile contre-argumente ensuite, citant une série de jurisprudence. Et c’est là que le premier soucis apparaît.

L’avocat de la défense note dans sa réponse qu’il n’arrive pas à trouver la jurisprudence en question dans les bases de données juridiques. Ce n’est pas un problème courant, et ça attire immédiatement l’attention du juge.

Les juges n’aiment pas particulièrement lire des argumentaires basés sur une jurisprudence inexistante. Ici, il ordonne donc à l’avocat de la partie civile de fournir une copie de tous ces fameux cas cités et introuvables.
Ce dernier obtempère quelques jours plus tards… mais les pièces qu’il produit posent toujours soucis à la défense.

Dans cette lettre au juge, l’avocat de la défense remet en cause l’authenticité des documents fournis, indiquant qu’aucune référence à ces documents n’existent dans les bases de données habituellement utilisées par les juristes américains.
Et là, soudainement, l’affaire prend une tournure très différente. Le juge ne s’intéresse plus tellement à Mata v. Avianca. Il veut comprendre exactement ce qu’il s’est passé avec cette jurisprudence perdue.

Le juge ne mâche pas ses mots: six des cas cités par la partie civile sont apparemment des fausses décisions, avec de fausses citations. L’avocat de la partie civile devient soudainement l’accusé.
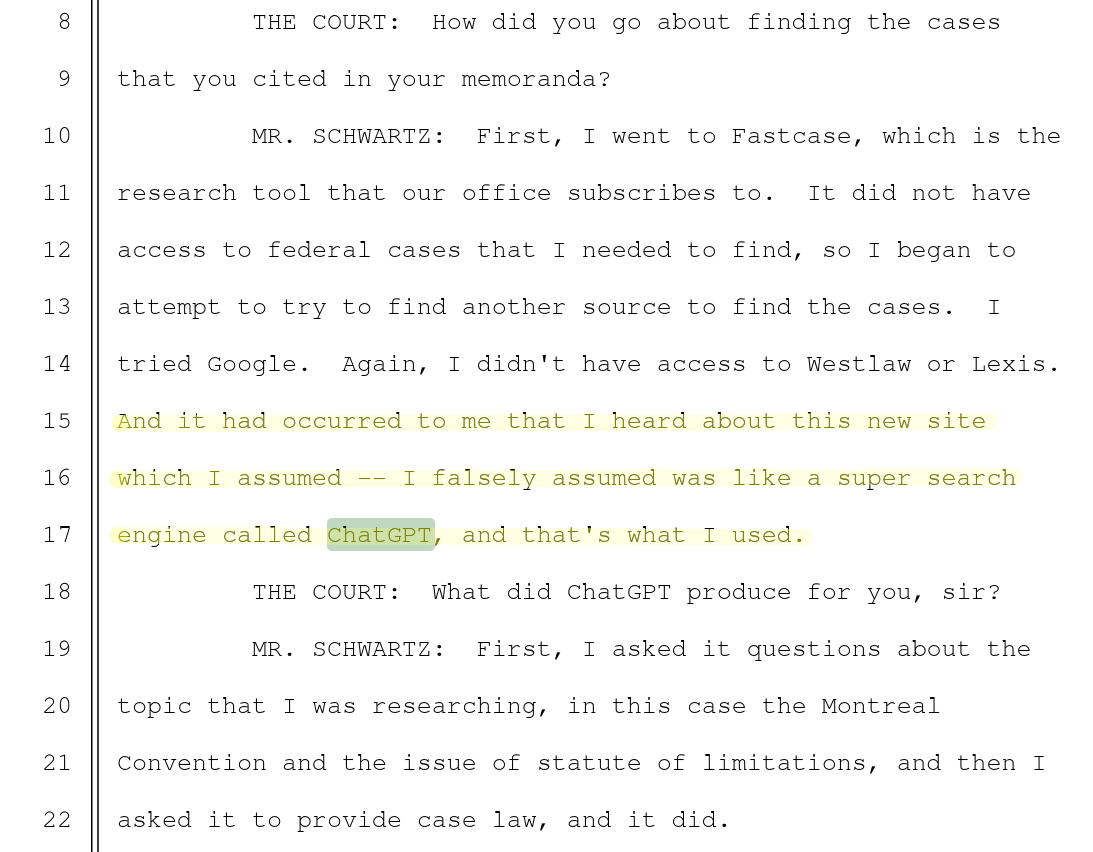
Lors de la déposition de l’avocat de la partie civile, il explique qu’il a récemment entendu parler de ce formidable outil appelé “ChatGPT”, qu’il a pris pour un super moteur de recherche.
ChatGPT lui a d’abord fourni son argumentaire puis, plus tard, à écrit les jurisprudences demandées. Mais ChatGPT n’a pas accès aux bases de données juridiques, et a inventé ses sources.
L’avocat de la partie civile, et son cabinet d’avocat, finissent par être sanctionnés par une amende… et le juge décide en faveur de la défense.
Mata v. Avianca est déjà de “l’histoire ancienne” au vu du rythme des nouvelles sur l’intelligence artificielle. On ne savait pas encore bien comment tout cela fonctionnait, et il a utilisé une version maintenant obsolète de ChatGPT.
Sûrement que ce genre de soucis n’arriverait plus aujourd’hui ?

(à propos d’un Hoverboard qui a explosé, blessant des enfants de la famille Wadsworth)
Début 2025, Stéphanie Wadsworth attaque la chaîne de supermarché Walmart et le fabricant de vélos électrique Jetson pour réclamer des dommages et intérêts suite à l’explosion d’un Hoverboard qui a blessé ses enfants.

Je vais passer sur les détails de l’affaire, et arriver directement au passage maitnenant familier: toute une série de cas cités par la partie civile n’ont pu être retrouvés par la défense.
Le juge demande à la partie civile de s’expliquer. Encore la faute à ChatGPT ?

C’est initialement un peu moins clair: l’avocat de la plaignante admet que les cas cités n’existent pas, et indique que leur “plateforme d’intelligence artificielle interne” les a hallucinés.

Dans les diverses dépositions des membres de la firme Morgan & Morgan, qui emploie l’avocat concerné, on trouve un peu plus de détails: ils ont depuis quelques mois lancés un outil interne privé, MX2.law.
Cet outil est supposé être spécialement conçu pour la firme, et capable d’assister les juristes dans leur travail.
Cela ne l’empêche pas d’inventer du droit de toute pièce.
Nous ne sommes pas à l’abris de ce genre de choses en Belgique. À ma connaissance, il n’y a pas encore eu de cas de fabrications de toutes pièce de jurisprudence (qui a moins d’importance aussi dans le droit belge que dans le droit américain), mais on a par exemple déjà eu un avocat qui a présenté ChatGPT comme “une source neutre qui a analysé la législation” dans son argumentaire (RTL info) dans une affaire de traffic de cocaïne. ChatGPT n’est absolument pas capable d’effectuer une analyse. Anecdotiquement, le procès ne s’est pas soldé en faveur de ses clients (RTBF), même si le jugement n’a probablement pas été affecté dans un sens ou l’autre par l’utilisation de ChatGPT.

Tout ça, c’était les États-Unis. En Belgique, heureusement, on sait ce qu’on fait, n’est-ce pas ?
Parlons un peu de Welexit. Welexit est une startup Wallonne, issue d’une société appelée Kulash LY. À la base, leur idée est de faire un réseau d’avocats qui met rapidement en correspondance des clients potentiels avec des avocats compétents pour leur problème.
Ils publient aussi des “guides juridiques” qui expliquent les droits et les recours légaux possibles dans toute une série de situations fréquentes.
 Avril 2023: lancement par Welexit
de “mylittlelawyer.be”, une intelligence artificielle qui répond à
toutes vos questions sur le droit belge…
Avril 2023: lancement par Welexit
de “mylittlelawyer.be”, une intelligence artificielle qui répond à
toutes vos questions sur le droit belge…
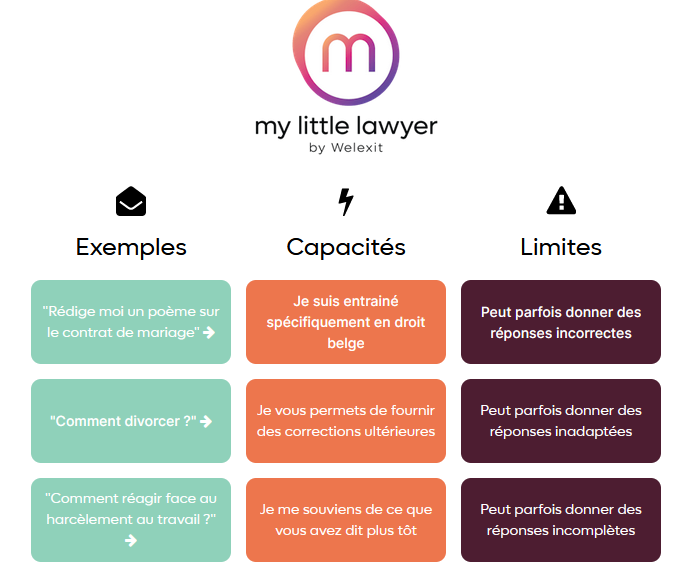
Puis, ChatGPT arrive, et tout le monde veut sauter sur la manne de financement pour tous les projets branchés “IA”. Welexit lance “My Little Lawyer”, une intelligence artificielle spécialement entraînée sur le droit belge, capable d’assister les citoyen.ne.s de notre pays.
L’interface est complètement identique (quoique plus colorée) à celle de ChatGPT, et les “limites” indiquées semblent légèrement inquiétantes pour un système supposé fournir du conseil juridique: “des réponses incorrectes”, “inadaptées” ou “incomplètes”, ce n’est pas rassurant.
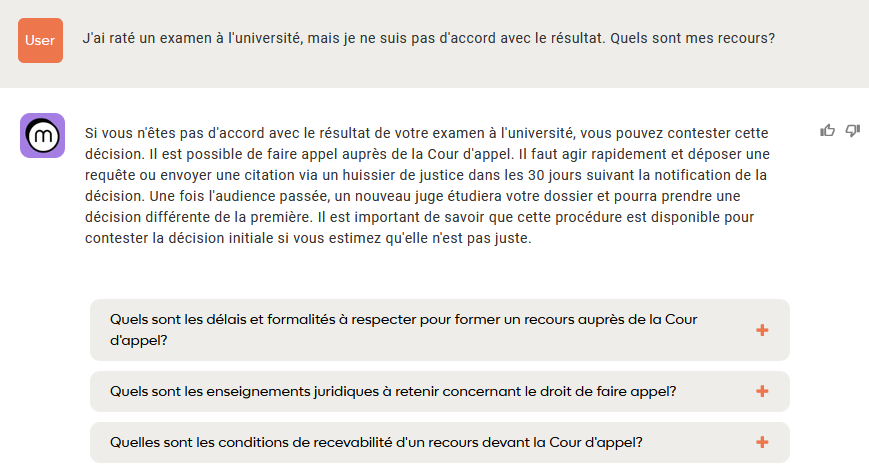
Pour le cours de l’an dernier, j’avais fait un rapide test. En cherchant une question légale qui pouvait parler à des étudiant.e.s, j’ai posé la question de savoir comment faire un recours lorsqu’on n’est pas d’accord avec le résultat d’un examen.
Le résultat était, effectivement, incorrect, inadapté et incomplet. Un point pour l’honnêteté.

Pour cette année, j’ai voulu retester le système pour voir s’il s’était amélioré entre temps.
Malheureusement, le site de MyLittleLawyer est inacessible, celui de Welexit fait maintenant la promotion de casinos en ligne, et la société Kulash LY est en faillite.
Service permettant de faire une recherche, sur base d’une image, pour voir s’il existe des marques déposées similaires.
Exemple:

Avec ces trois exemples, j’espère qu’on peut déjà voir que ChatGPT et autres “chatbots” similaires ont du mal à traiter les questions de droit. Mais il y a d’autres types d’intelligence artificielle.
Si l’on va voir du côté d’une institution publique réputée, telle que l’office des brevets du Bénélux, on pourra certainement trouver des systèmes fiables, non?
Voyons par exemple le système de recherche du registre des marques. L’objectif est de voir, sur base d’une image ou de mots clés, s’il existe des marques déposées antérieures similaires à celle que vous vous apprêtez à soumettre.
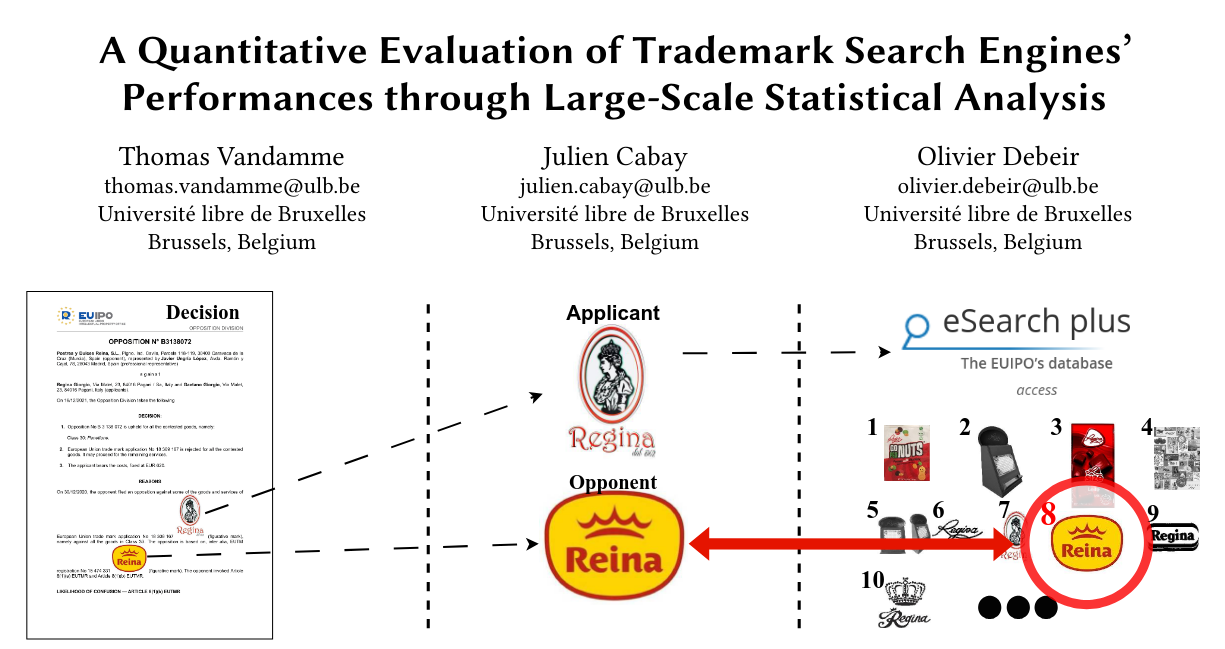
Un de mes collègues, Thomas Vandamme, s’est intéressé avec Julien Cabay, spécialiste de la propriété intellectuelle que vous aurez peut-être en cours en Master, à l’évaluation de ces outils de recherche.
Décision: risque de confusion

Décision: pas de risque de confusion
Risque de confusion dépend: des biens et services vendus, de l’originalité de la chose représentée, du public cible, etc…
J. Cabay, “Computing Likelihood of Confusion? Lessons from IPSAM”, Trademark Law Institute Symposium on Proportionality in Trademark Law, Maastricht University, 6-7 June 2024
Le résultat de leurs recherche montre assez clairement que non, ces outils ne marchent pas du tout. Pourquoi ? Parce qu’ils essaient de résoudre un problème de droit – celui du “risque de confusion” entre deux marques – avec une approche d’ingénieurs – calculer la similarité entre deux images.
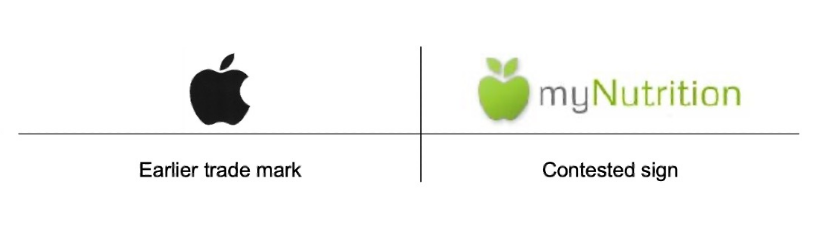
Mais le “risque de confusion” au sens du droit des marques est beaucoup plus complexe qu’une question de similarité ! Par exemple, ici, on a deux oppositions par Apple a des marques qui utilisent une pomme dans leur logo. Pour myNutrition, le juge a décidé qu’il y avait un risque de confusion, et la marque a été refusée. Pour SuperVida, par contre, pas de soucis.
Pourquoi ? Parce que le risque de confusion dépend de beaucoup de choses, y compris du contexte dans lequel ces marques évoluent, de leur public cible, de l’environnement culturel de ce public cible, etc.
Le droit, c’est compliqué !
La première chose importante à noter, c’est que l’intelligence artificielle n’est pas un concept nouveau. Dès les débuts de l’informatique, dans les années 40-50s, on se demande jusqu’où ces “ordinateurs” peuvent aller, et s’ils seraient capable de simuler un cerveau humain. Le terme lui-même est inventé en 1955, principalement comme un terme “marketing” un peu fourre-tout. Il n’y a pas une définition claire de l’IA, mais on peut distinguer deux grands champs d’application du terme: la recherche en sciences cognitives qui cherche à simuler l’intelligence humaine (ou animale) pour mieux la comprendre, et la recherche en informatique qui cherche à résoudre des tâches “cognitives” sans nécessairement que la méthode de résolution soit similaire à la façon dont un humain aborderait la tâche.
Il est donc important de bien se rendre compte que quand on parle d’intelligence pour une machine on parle de quelque chose de très différent que quand on parle de l’intelligence d’un être humain.
Exemple: un robot qui évite les obstacles. Imaginons
que le robot a un capteur de toucher (TOUCHE), un moteur
pour avancer (AVANCE), un moteur pour tourner
(TOURNE). Un programme “expert” pourrait
ressembler à:
REPETER:
SI TOUCHE:
TOURNE
SINON:
AVANCEPour comprendre ce que font les intelligences artificielles, il faut bien les remettre à leur place: ce sont des programmes informatiques.
Un programme informatique est, essentiellement, une suite d’instructions simples qu’on donne à l’ordinateur. Tout ce que fait l’ordinateur, c’est exécuter ses instructions. C’est vrai pour les programmes les plus simples, comme pour les intelligences artificielles les plus complexes. Un ordinateur ne fait jamais rien par lui-même.
Parmi les programmes qui cherchent à résoudre des tâches “cognitives”, on peut en distinguer différents types: les systèmes experts, dont toutes les étapes de décision sont explicitement déterminées par des expert.e.s humains; les systèmes à apprentissage, où certains paramètres de décision vont être ajustés en fonction d’exemples fournis au système; les IAs génératives, qui produisent du texte, des images, etc., et qui ne sont qu’une petite partie des IAs en général.
Si notre robot est une voiture qui doit naviguer dans un environnement complexe (par exemple: la place Meiser à l’heure de pointe)… il est impossible de décrire toutes les règles manuellement. Dans un système à apprentissage, on définit les “entrées”, les “sorties” et un modèle mathématique entre les deux. On utilise ensuite des exemples d’apprentissage pour ajuster les paramètres du modèle.
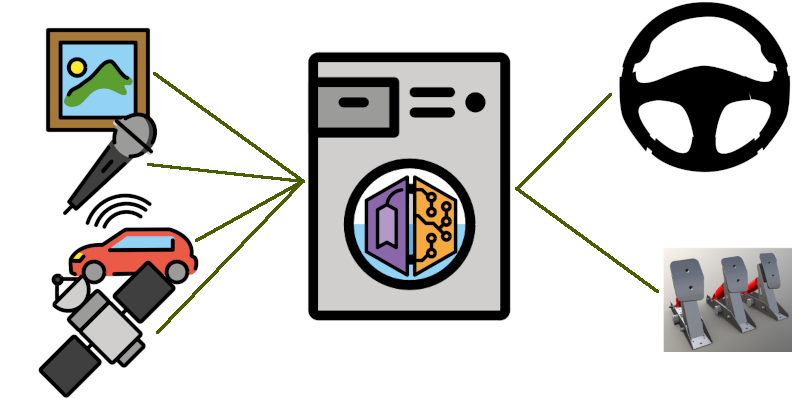
Le principe du système à apprentissage est de définir les entrées et les sorties du système, ainsi que la “forme” du lien mathématique entre les deux. Pour notre exemple de système de conduite automatique, les entrées seraient tous les capteurs – vidéo, radar, audio, LIDAR, GPS – qui fournissent des données numériques au système. Les sorties seraient les commandes à envoyer au volant ou aux “pédales” pour tourner, accélérer, ralentir.
Comment faire le lien entre les deux ? Via un modèle mathématique.
Modèle mathématique ?
Imaginons que nous n’avons qu’une seule entrée dans notre système: \(x\). Et une seule sortie, \(y\). Le modèle mathématique le plus simple serait le modèle linéaire: \(y = \textcolor{red}{a}x + \textcolor{red}{b}\), où \(\textcolor{red}{a}\) et \(\textcolor{red}{b}\) sont des paramètres à ajuster en fonction d’exemples:
| \(x\) | 8 | -3 | 5 | 1 | -1 |
| \(y\) | 21 | -3 | 14 | 7 | 2 |
Apprentissage: quelles sont les valeurs de \(\textcolor{red}{a}\) et \(\textcolor{red}{b}\) telles que \(y - \textcolor{red}{a}x - \textcolor{red}{b}\) est aussi proche de zéro que possible pour tous les exemples ?
Un modèle mathématique est une relation entre les entrées et la sortie, qui prend généralement la forme d’une équation (plus ou moins compliquée) avec des paramètres. Ce qu’on appelle “entrainement” ou “apprentissage” est l’ajustement de ces paramètres pour que la relation mathématique soit “correcte”, c’est-à-dire que lorsqu’on évalue l’équation mathématique \(y = ax + b\) en remplaçant \(x\) et \(y\) par les valeurs d’exemples, on obtient quelque chose d’aussi proche que possible de l’égalité pour tous les exemples.
Apprentissage: quelles sont les valeurs de \(\textcolor{red}{a}\) et \(\textcolor{red}{b}\) telles que \(y - \textcolor{red}{a}x - \textcolor{red}{b}\) est aussi proche de zéro que possible pour tous les exemples ?
| \(x\) | 8 | -3 | 5 | 1 | -1 |
| \(y\) | 21 | -3 | 14 | 7 | 2 |
| \(ax+b\) si \(a=0,b=0\) | 0 | 0 | 0 | 0 | 0 |
| \(ax+b\) si \(a=2,b=4\) | 20 | -2 | 14 | 6 | 2 |
\(\rightarrow y = \textcolor{red}{2}x + \textcolor{red}{4}\) semble donner de meilleurs résultats que \(\rightarrow y = \textcolor{red}{0}x + \textcolor{red}{0}\). \(a=2, b=4\) sont donc des meilleures valeurs pour les paramètres du modèle.
(les valeurs “optimales”, ici, seraient \(a \approx 2.12\), \(b \approx 3.95\))
Avec notre exemple ici, on peut par exemple voir que si on met \(a=0, b=0\), on est très loin de l’égalité, alors que si on a \(a=2, b=4\), on se rapproche beaucoup plus du résultat attendu: une bonne méthode d’apprentissage va nous permettre de trouver des valeurs pour \(a\) et \(b\) qui nous permettent de nous rapprocher au mieux de cette égalité.
Réseau de neurones artificiels ?
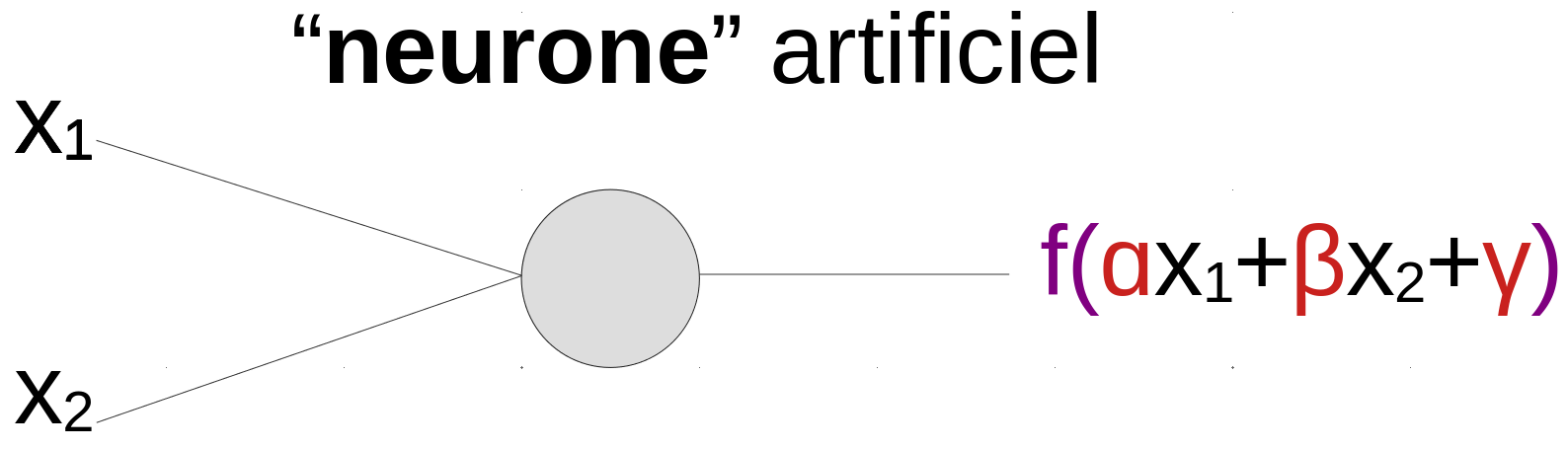
Le réseau de neurones est une façon de construire une fonction mathématiques aussi complexe que nécessaire à partir d’éléments très simples, en grands nombres et interconnectés.
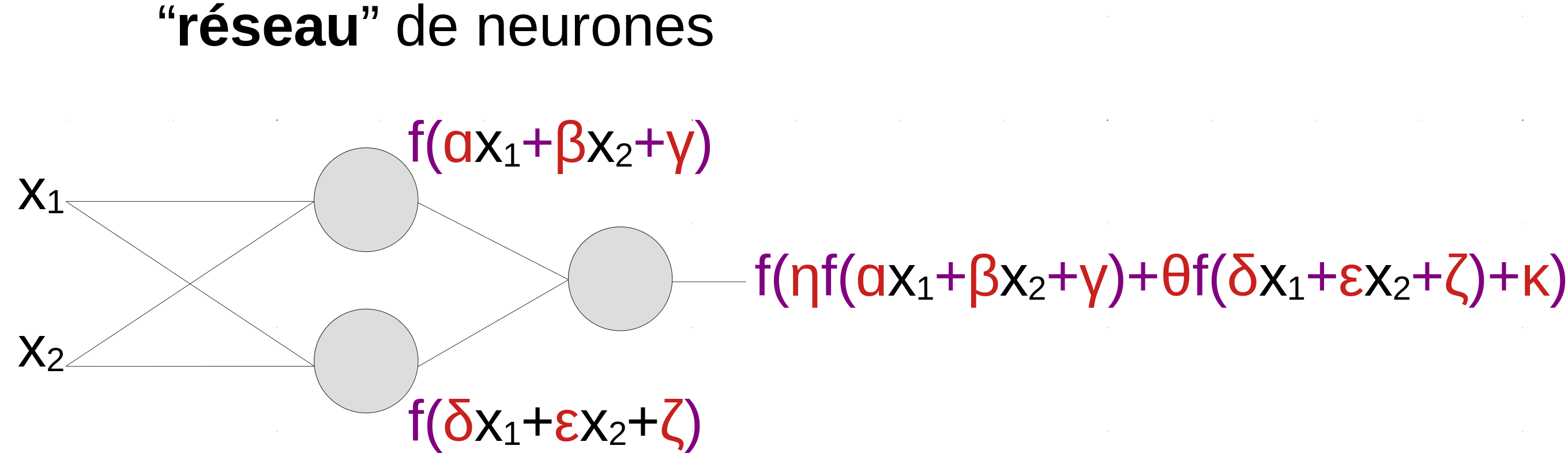
(dans les “grands réseaux”: millions de neurones, millions ou milliards de paramètres, architectures complexes, et différents “types” de neurones, souvent organisés en “couches” successives…)
En pratique, on a besoin de modèles mathématiques capable de représenter des relations beaucoup plus complexes. Une manière d’y arriver est d’utiliser des réseaux de neurones artificiels, inspirés (initialement) des neurones humains. Le neurone artificiel réalise une opération quasi-linéaire sur ses entrées. Mais sa sortie devient ensuite une entrée d’autres neurones, et c’est en combinant les neurones au sein d’un réseau qu’on obtient une fonction complexe, qui est une fonction simple de fonctions simples de fonctions simples de fonctions simples etc… des entrées du système.
Un grand modèle de langage (Large Language Model) est un réseau de neurones artificiels entraîné pour la génération de texte.
Exemple:
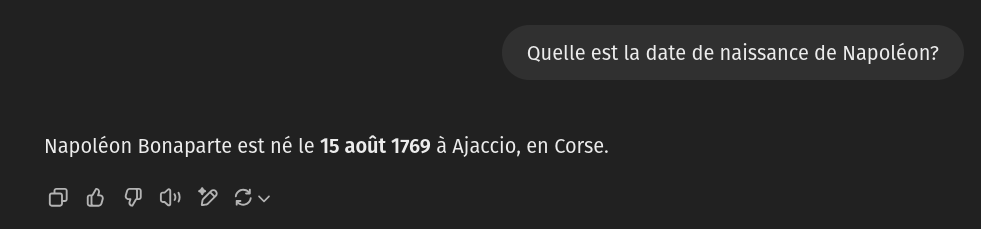
“La date de naissance de Napoléon est”
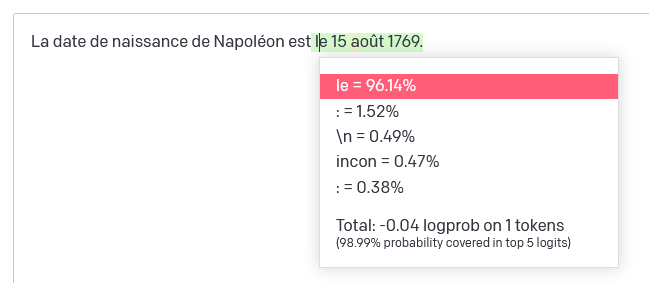
OpenAI fournit un outil qui permet d’explorer les probabilités de “prochain token” pour un modèle donné. On peut ainsi voir que, si on commence avec la phrase “La date de naissance de Napoléon est”, le réseau estime que ” le” est de très loin le token suivant le plus probable. Mais d’autres possibilités ont aussi une (plus) faible chance d’apparaître: “:”, un retour à la ligne (“”)… ou le token ” incon”, indiquant que le modèle de langage pourrait sans doute compléter par “La date de naissance de Napoléon est inconnue”, dans environ 5 cas sur 1000.
You are a ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.
Knowledge cutoff: (...)
Whenever a description of an image is given, create a prompt that dalle can use to generate the image and abide to the following policy: (...)
- Do not create any imagery that would be offensive. (...)
You have the tool `browser` with these functions:
`search(query: str, recency_days: int)` Issues a query to a search engine and displays the results. (...)
Never write a summary with more than 80 words. (...)
User: Quelle est la date de naissance de Napoléon?
ChatGPT:Le “prompt” donné ici est adapté de: https://github.com/LouisShark/chatgpt_system_prompt/blob/main/prompts/official-product/openai/gpt-4-gizmo-20231116.md et est donné à titre d’exemple. La méthode utilisée pour récupérer ce prompt n’est pas exacte: ChatGPT n’est pas capable d’introspection et ne renvoie pas “réellement” son prompt quand on le lui demande. Mais il renvoie sans doute quelque chose de similaire.
Tout ce texte est donné en entrée au modèle de langage (par exemple GPT-4o), qui va prédire le prochain token: . Ensuite… le programme renvoie le texte complété, et recommence.
You are a ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.
Knowledge cutoff: (...)
Whenever a description of an image is given, create a prompt that dalle can use to generate the image and abide to the following policy: (...)
- Do not create any imagery that would be offensive. (...)
You have the tool `browser` with these functions:
`search(query: str, recency_days: int)` Issues a query to a search engine and displays the results. (...)
Never write a summary with more than 80 words. (...)
User: Quelle est la date de naissance de Napoléon?
ChatGPT: NapProchain token:
Le processus est répété jusqu’à atteindre un token spécial “fin de texte”. Le programme prend ensuite toute la partie qui a été ajoutée au prompt initial:
Et l’affiche dans la “conversation”:
Si on continue la conversation, le processus est relancé, avec l’historique de la conversation rajouté dans le contexte.
Versions récentes de ChatGPT (ou Perplexity, ou autres): peuvent aussi effectuer des recherches sur le web.
Si les token générés contiennent certaines séquences
particulières (exemple:
search("date de naissance Napoléon Bonaparte"), le
programme va lancer une recherche (via Bing, Google, etc.), récupérer le
contenu des pages, et les rajouter au contexte comme
informations disponibles pour construire la réponse.
Notez que ces fonctionnalités dépendent largement de programmes écrits (et maintenus) par des humains et qui ne passent pas du tout par le modèle de langage en lui-même.
L’intelligence est un concept fondamentalement humain (et déjà mal défini pour l’humain !) Essayer de l’appliquer à des machines n’a pas beaucoup de sens.
Quand on évalue un programme informatique, on évalue sa capacité à résoudre des tâches précises, dans certaines conditions bien définies.
Par exemple: est-ce que le programme est capable de détecter les mitoses cellulaires dans des images de biopsie de cancer du sein prises avec un microscope et numérisées avec une résolution de 0.20µm/px ?
Une fois que la tâche est précisément définie, on peut déterminer des métriques d’évaluation, qui peuvent nous indiquer quels programmes fonctionnent mieux pour résoudre la tâche.
Exemple:
Le choix de la métrique peut avoir un impact important sur l’interprétation des résultats.
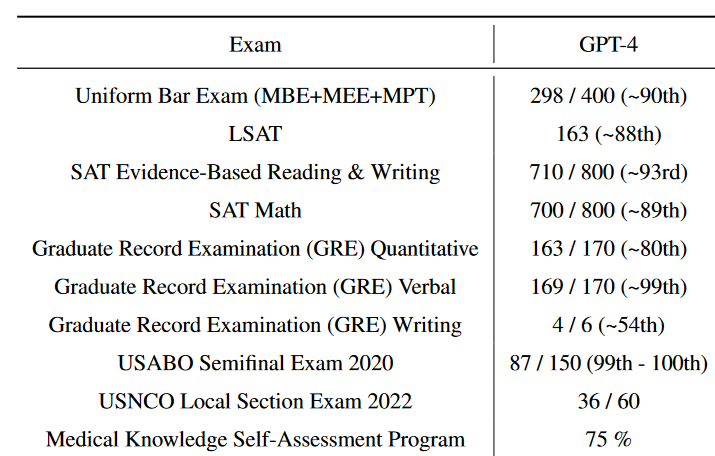
GPT-4 est capable de très bien réussir un examen de droit standardisé.
Est-ce que ça prouve…
Derrière les sociétés qui font de l’IA se trouvent des enjeux financiers énormes. Une certaine dose de scepticisme est nécessaire face aux résultats annoncés. Les startups sont financées sur le “hype”, pas sur les résultats.
Pour correctement évaluer un outil d’intelligence artificielle:
Attention, l’évaluation ne doit pas être uniquement basée sur la “justesse” du résultat obtenu. Les questions éthiques et légales peuvent (doivent?) faire partie des critères d’évaluation.
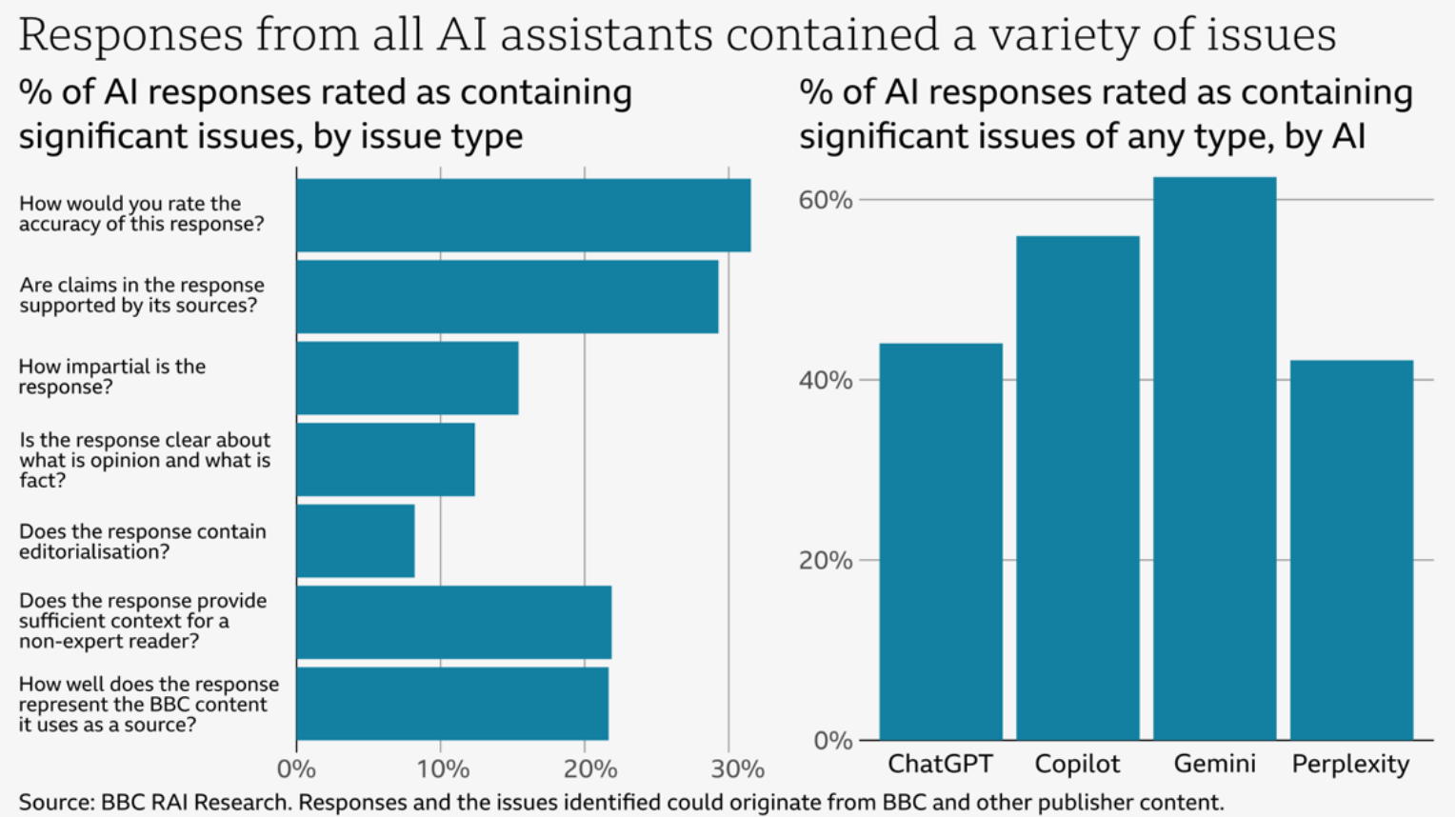
Un exemple d’évaluation, réalisé par la BBC. Après qu’Apple Intelligence ait complètement détourné le sens de leurs articles dans des résumés automatiques, la BBC a voulu objectiver la capacité des IA génératives à expliquer le contenu de leurs articles.
Résultat? Entre 40 et 60% des réponses selon les outils contiennent des problèmes significatifs. On a donc ici un bon exemple d’une évaluation qui a du sens: la BBC a identifié une tâche précise, et objectivé l’incapacité de ces outils à la réaliser de manière satisfaisante – quel que soit le score qu’ils puissent obtenir sur des “benchmarks” de leurs choix.
Parmi les aspects éthiques, on peut commencer par pointer le coût énergétique énorme des outils génératifs. Avec le problème de la “course aux armements”: pour gagner quelques précieux points dans les benchmarks et “battre” la compétition, les géants de la tech doivent dépenser des quantités exponentielles d’énergie, pour au final des améliorations de plus en plus mineures.
Notons aussi l’aspect humain: pour éviter que le réseau n’apprenne des contenus “problématiques”, il faut les filtrer… tâche ingrate et difficile laissée à des travailleurs exploités de pays en voie de développement.

Plus on utilise des IA génératives, moins on réfléchit à ce qu’on fait et moins on vérifie le résultat. L’usage est associé à une diminution de la créativité et du sens critique.
Prenez garde au technosolutionnisme: essayer de résoudre des problèmes sociétaux (exemple: on manque de juges, la justice est trop lente!) avec une solution technologique (remplaçons les juges par des IAs!) est souvent une manière d’éviter de devoir adresser le coeur du problème…
…et une excuse pour réduire des coûts, peu importe l’impact à long terme sur la qualité des services.
Notons aussi que l’idée que “ça va tant que l’humain garde la décision finale” ne fonctionne pas vraiment.
Dès que les outils IA deviennent la norme dans un domaine, on attend des utilisateurs un gain de productivité incompatible avec une vérification approfondie des résultats. Si on donne des IAs aux juges qui leur “prémâche” le travail, ils n’auront pas le temps de remettre en question les conclusions de l’IA et, sauf erreur flagrante, se contenteront vite de valider les propositions de la machine, manquant au passage les erreurs plus difficiles à détecter.
Scénario hypothétique:
Un juriste experimenté donne des tâches “simples” (et/ou rébarbatives…) à des juristes débutants. Ceux-ci acquièrent de l’expérience qui leur permet de devenir à leur tour des juristes expérimentés.
Mais maintenant, les juristes expérimentés utilisent leur expérience pour fournir des données de qualité et entraîner des systèmes d’intelligence artificielle pour les aider dans les tâches “simples”. Ils n’ont plus besoin de juristes débutants.
Les juristes expérimentés deviennent des juristes retraités. Les juristes débutants ont disparus. Le système d’intelligence artificielle ne fonctionne plus, faute des corrections apportées par les juristes expérimentés.
Cadre légal autour des outils d’intelligence artificiel est changeant (ex: AI act).
Zones grises autour de:
Utilisation de l’IA: gare au plagiat “accidentel”. L’IA est incapable de correctement citer toutes ses sources. Elle peut transformer le sens, retirer du contexte, mal attribuer, voir plagier verbatim sans citation. Si l’IA plagie et que vous vous faites prendre… ce n’est pas l’IA qui subira les conséquences !
Questions, remarques, commentaires ?